
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/2ffa798b.d6b1b691.2ffa798c.d6d0570d/?me_id=1213310&item_id=20813919&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F1388%2F9784295601388.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/2ffa798b.d6b1b691.2ffa798c.d6d0570d/?me_id=1213310&item_id=20786713&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F1364%2F9784295601364.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")


この記事が役立つ方
・Stable diffusionやNovelAIで版権キャラを出力したいが、うまく出来ない
・版権キャラを描く方法にはどのような方法があるのか知りたい
はじめに
Stable diffusionやNovelAIといったイラスト生成AIは、簡単に熟練したイラストレーターが描いたようなイラストが生成できると昨今話題になっています。
ところで、このイラストAI、皆さんはどのような事がしたくて使っていますか?
綺麗なイラストをAIに描かせてみたい、イラストを描くアイデア作りに使いたい等、色々な目的があると思いますが、おそらく少なくない方が望んでいるのはこれじゃないでしょうか。
「好きなシチュエーションで好きなキャラに好きなポーズをさせたい!」
分かりますよ。私もそうです。
さぁ、皆さん、好きなキャラの生成のお時間です!
ここではNovelAIに「ゆるキャン△」から犬山あおいちゃんを描いてもらいましょう!
プロンプト:inuyamaaoi,1 girl, full body
セット!
出力!
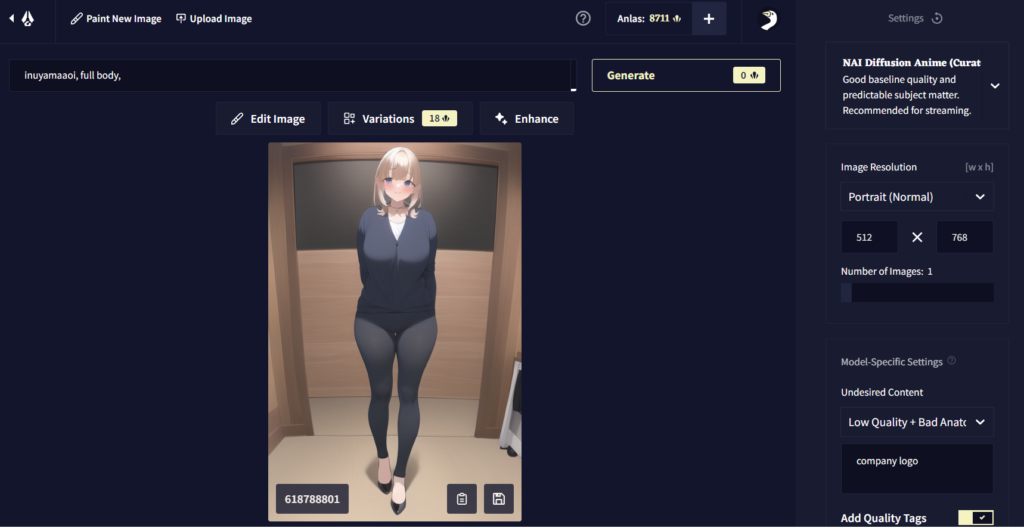
「誰だ、おめぇ…」
と、なるのが、AIイラスト初心者が必ず通る道です。
でもネットには、版権キャラの特徴をしっかりとらえたAIイラストが溢れています。これらは一体どうやって描いているのでしょうか?
という訳で、今回は、版権キャラを描く方法にはどのようなものがあるのかを解説したいと思います。
版権キャラを描く方法
それでは早速、版権キャラを描く方法にはどのようなものがあるのか紹介していきましょう。私の知っている手法を紹介しますが、私の知らない手法もきっとあると思います。網羅的なものではないことをご理解下さい。
なお、初心者におすすめするのは、NovelAIユーザーは③、Stable diffusionユーザーは⑤です。④・⑤はNovel AIでは現状難しいです。
①プロンプトを工夫し、キャラの特徴を記述する
②似たような画像を用意し、i2iで描写する
③学習モデルのデータ内に既に学習されてる、キャラ用タグプロンプトを入力する
④自力でキャラを学習させる(textual inversion,dreambooth,Loraなど)
⑤配布されているLoRAやTI学習データをダウンロードし、既存の学習モデルに組み込む
①、②は手軽だけど再現性に限界がある、③は強力だけれど範囲が狭い、④は強力で自由度が高いけど難しい、⑤は④を他力本願で利用する感じです。
それぞれの手法のメリット・デメリットは以下のような感じです。
プロンプトを工夫し、キャラの特徴を記述する
〇どのAIでも可能
〇シンプルなキャラなら十分対応できる可能性がある
〇他の手法と組み合わせることが出来る。
×細かい特徴を記述するのは難しい。
×この手法だけで複雑なキャラを再現するのは非常に難しい
似たような画像を用意し、i2iで描写する
〇プロンプトだけでは手の届かない特徴を命令する事が出来る
×元絵を準備する必要がある
×他の方が描いた絵を元絵とした場合、著作権侵害となる可能性がある
×キャラ似せの観点からすると、精度はイマイチ
学習モデルのデータ内に既に学習されてる、キャラ用タグプロンプトを入力する
〇例えば「hatsunemiku(初音ミク)」というプロンプトを入力するだけで、初音ミクっぽいイラストを高精度で描いてもらう事が可能。
×データ内に無いキャラは描けない。描けた場合もキャラによって精度に大きくばらつきがある。
自力でキャラを学習させる(textual inversion,dreambooth,Loraなど)
〇圧倒的に再現性や自由度が高い。
×導入・準備共に非常に手間である。
×許可なく他人の絵を学習させた場合、著作権侵害になる可能性がある。
×高いPCスペックを要求される場合がある。
配布されているLoRAやTI学習データをダウンロードし、既存の学習モデルに組み込む
〇上記に挙げた自力学習のメリットをそのまま低い労力で得ることが出来る
×配布されていないキャラの再現は出来ない
以上がそれぞれの手法の特徴になります。
それでは、それぞれの手法を詳しく見ていきましょう
プロンプトを工夫し、キャラの特徴を記述する
最も正攻法とも言える方法です。例えば、アニメ「氷菓」の千反田えるを描きたいとしましょう。えるちゃんの特徴と言ったら、「おかっぱ」「黒髪ロングヘア―」「セーラー服」あたりになるので、プロンプトを以下のように設定して描いてみます。
プロンプト:bowl cut hair,black hair,long hair, school uniform,
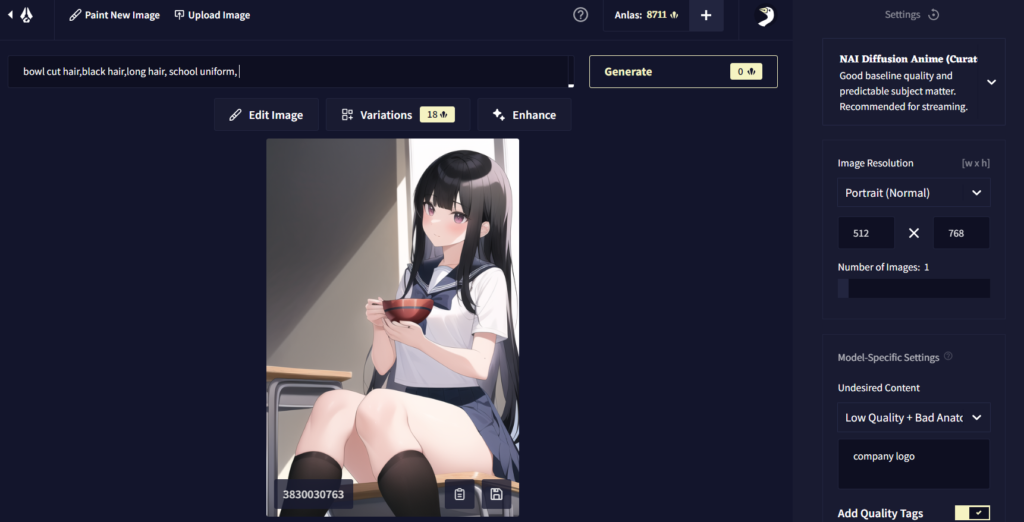
なんとなくそれっぽい感じにはなりました。
このように、ある程度のキャラの方向性といったものは、この手法で指示することが出来ます。
しかし、昨今のアニメやゲームのキャラは、プロンプトによる指示だけではどうしようもないくらい、特徴的だったり複雑なシンボルを持っています。
そのため、例で挙げた千反田えるのようなシンプルなキャラならともかく、昨今のソーシャルゲームのキャラのような複雑なキャラはこの手法で描くのは難しいでしょう。
ただ、この手法のいいところとして、他の手法と組み合わせる事が出来るため、調整の手段としてプロンプトの工夫はいずれにせよやった方が良いです。
似たような画像を用意し、i2iで描写する
i2iとは、用意した画像を元にそれに似通った画像を描く技術です。例えば顔と服と髪飾りをざっくりと描いた落書きを用意して、それをイラスト生成AIに読み込ませて、プロンプトによる指示と組み合わせれば、より詳細に特徴を指示してイラストを描いてもらう事ができます。
ただ、i2iは構図や背景の方向性はよく読み込んでくれますが、正直キャラの特徴についてはあんまり…といった印象です。また、自分以外が描いた絵をi2iの元絵にすると、著作権侵害となる可能性もあるので、あまりおすすめできません。
学習モデルのデータ内に既に学習されてる、キャラ用タグプロンプトを入力する
データ内に情報のあるキャラならば、例えば「hatsunemiku」というタグを付けただけで、初音ミクのような緑髪でツーサイドアップで特徴的な髪飾りをしている女の子の絵が出力されます。
初音ミクのように、世にたくさんのイラストが出回っているキャラであれば、AIに学習されている可能性も高く、簡単にキャラを再現できます。特にNovelAIでは、学習モデルのデータを変更することが出来ないため、この手法が最強のキャラ似せ手法になります。
一方、欠点は言わずもがなですが、学習モデルにそのキャラに関するデータがなければ当然再現できません。いくら人気のキャラでも、そのモデルのデータ収集の後に有名になったキャラなどは、再現できるはずもありません。
幾万とあるキャラクターの中で、再現できるキャラは非常に限られているので、この手法は、一言で言うと、
「強力だが有効範囲の狭い手法」
と言えるでしょう。好きなキャラのタグが有効だったらラッキー、くらいに考えておきましょう。
自力でキャラを学習させる(textual inversion,dreambooth,Loraなど)
主にStable diffusionで使用可能な手法ですが、我々のようなエンドユーザーでも、学習データを作ったり、それを既存の学習データと混ぜる(マージするといいます)事が可能です。
その手法は実は色々あり、textual inversion,dreambooth,Loraなどはその一例になります。
どんなキャラでも学習次第で再現させる事が出来るのがこの手法の強みですが、一方でデメリットとして、導入の難易度が上記の3手法と比べると圧倒的に高い事、手法によっては高いグラフィックボードの性能を要求される事、学習元のデータを準備しなければいけない事などが挙げられます。
一言で言うと、
「難易度は高いが最強の手法」
といった所です。
配布されているLoRAやTI学習データをダウンロードし、既存の学習モデルに組み込む
2-4の手法でできた学習データを公開・共有しているサイトがあり、そこから学習データをダウンロードすることで、2-4の手法のメリットを労せずして得る事が出来ます。
配布サイトは以下のようなもの。デベロッパーサイトのHuggingfaceでも公開している場合があります。

簡単に最高レベルの再現が出来る可能性があるのがこの手法ですが、欠点としてはデータが公開されていないキャラは再現できない事、また、学習データの作成者の技量によって、キャラの再現性やポーズ等の柔軟性に大きく差がある事が挙げられます。
終わりに
以上がキャラ似せの手法5つの紹介になります。いかがだったでしょうか?
詳しい手法の解説などは別ページに記載していこうと思います。 読んで頂き、ありがとうございました。
![]()

コメント